Próbkowanie danych w Google Analytics to bardzo ciekawe zjawisko, które dotyka wszystkich użytkowników GA przy większej skali. W ogromnym skrócie polega na dobieraniu kohorty bądź grupy podobnych odbiorców i przedstawianie ich jako jednego zbioru. Tak zorganizowane próbkowanie odciąża serwery przed nadmiarem zbędnych danych (duplikowanych) a zarazem pozwala wyciągnąć rzetelne i wiarygodne dane. Każdy raport GA ma jednak swoje własne limity o których informuje jeden kluczowy symbol. Zapraszam do lektury niniejszego wpisu aby zagłębić się w tajniki gromadzenia danych w G A!
Limity próbkowania danych
Przeogromna ilość danych przechodzi każdego dnia przez serwery Google, stąd byłoby niemożliwym zwracać każdemu jednemu użytkownikowi tego systemu 100% danych, biorąc pod uwagę, że każdy jeden raport wymaga przygotowania od nowa tych samych danych. Zacznijmy jednak od samego początku – od jakiej liczby zaczynają się ograniczenia? Jaka ilość danych jest wystarczającym źródłem informacji, aby zaufać wypróbkowanej liczbie? Spójrzmy na poniższe dane.
- 500 000 sesji na poziomie usługi
- 1 000 000 konwersji w raporcie „ścieżki wielokanałowe”
- 100 000 sesji w raporcie „wizualizacja ścieżki”
Google Analytics 360:
100 000 000 sesji na poziomie danych
Jak sprawdzić czy dane są próbkowane?
Wejdź na dowolny raport na swoim koncie Google Analytics. Na samej górze, po lewej stronie od nazwy raportu znajduje się tarcza. Sprawdź jaki ma kolor – zielona oznacza 100% danych, żółta sygnalizuje próbkowanie. Możesz wybrać spośród dwóch opcji: „krótszy czas reakcji” lub „większa precyzja”. Oczywiście ma to sens tylko przy raportach z dużą ilością danych.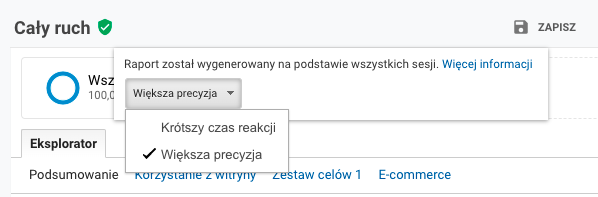
Jak unikać próbkowania danych?
Najważniejszym elementem w poszukiwaniu informacji z pomocą GA jest pytanie „czego właściwie potrzebuje?”. Czasem najlepszym sposobem jest korzystanie z domyślnych widoków danych w jak najprostszej formie. Aby zwrócić nam jak najbardziej precyzyjne informacja, GA grupuje podobne grupy danych, które mogą stanowić dla nas ważne informacje i zwraca nam spróbkowane dane.
Nie oznacza o jednak, że widzimy niepełne informacje o naszych użytkownikach. Mechanizm doboru użytkowników opiera się na kohorcie, czyli grupie podobnych zachowań czy wyszukiwań. Dzięki temu, czas reakcji systemu na nasze żądanie jest krótszy a na każdy raport nie musimy wyczekiwać w nieskończoność.
Innym najczęstszym rozwiązaniem jest wtyczka Supermetrics, która pozwala na pracę z danymi z Google Analytics np. w Google Sheet. Ma również inne zastosowanie jako liczne konektory z Google Data Studio, jest jednak płatna w zależności od liczby użytkowników z niej korzystających.
Zainteresował Cię temat równie mocno jak mnie? Zostawiam na koniec niezwykle ciekawe video z kanału Loves Data, w którym omówione są również inne metody unikania próbkowania.
Do przeczytania następnym razem!